(1)简介
机器行为及其相关算法虽然可以提供高度个性化和相关的服务和内容,但机器行为的有效性受到算法当前无法向用户解释其决策和操作的限制。
本研究基于韩国研究者申东熙(D. Shin)的可解释性对于用户感知影响的研究,面向中国人群,重点研究智能算法的可解释性对用户信任和对人工智能态度的影响,并对中国人群的情况与之进行比较研究。研究的理论基础是将基于人类慢速分析推理的“因果性或者因果关系”的概念理解为“可解释性”的先决条件和算法的关键线索,并通过测试它们如何影响用户对人工智能驱动服务的感知性能来检验它们与信任的关系。研究试图揭示因果性和可解释性的双重作用,即其与信任和后续用户行为的潜在联系。
(2)研究假设:人工智能中的因果性与解释性
为了与申东熙的研究有所差异又便于后续的比较研究,研究假设主要从申东熙的研究中选取;但本研究在研究的情境、对象和分析方法上均有较大差异。研究提出两个基本概念:因果性被认为是解释性的前置因素,解释性被认为是“公平性、责任、透明度(简称FAT)”的前提。因此,本研究提出以下假设:
第一组假设是人们如何使用人工智能感知/评估可解释性。
H1:可解释性积极影响用户对智能算法透明度的感知。
H2:可解释性积极影响用户对智能算法公平性的感知。
H3:可解释性积极影响用户对智能算法责任的感知。
第二组假设是因果性,即可解释性的质量与前提。具体假设包括:
H4:因果性积极影响智能算法的可解释性。
第三组假设是解释的信心与信任。具体假设包括:
H5:感知的透明度积极影响用户对智能算法的信任。
H6:感知公平性积极影响用户对智能算法的信任。
H7:责任积极影响用户对智能算法的信任。
第四组假设是算法性能。具体假设包括:
H8:信任对人工智能的感知性能有显著影响。
(3)实验设计
本研究共招募了280名被试,被试仅限于具有智能算法服务经验(自动推荐、内容建议等)的用户,以确保研究的学习成本可控。为了保证回答的可靠性和有效性,研究还增加了一系列验证确认问题。
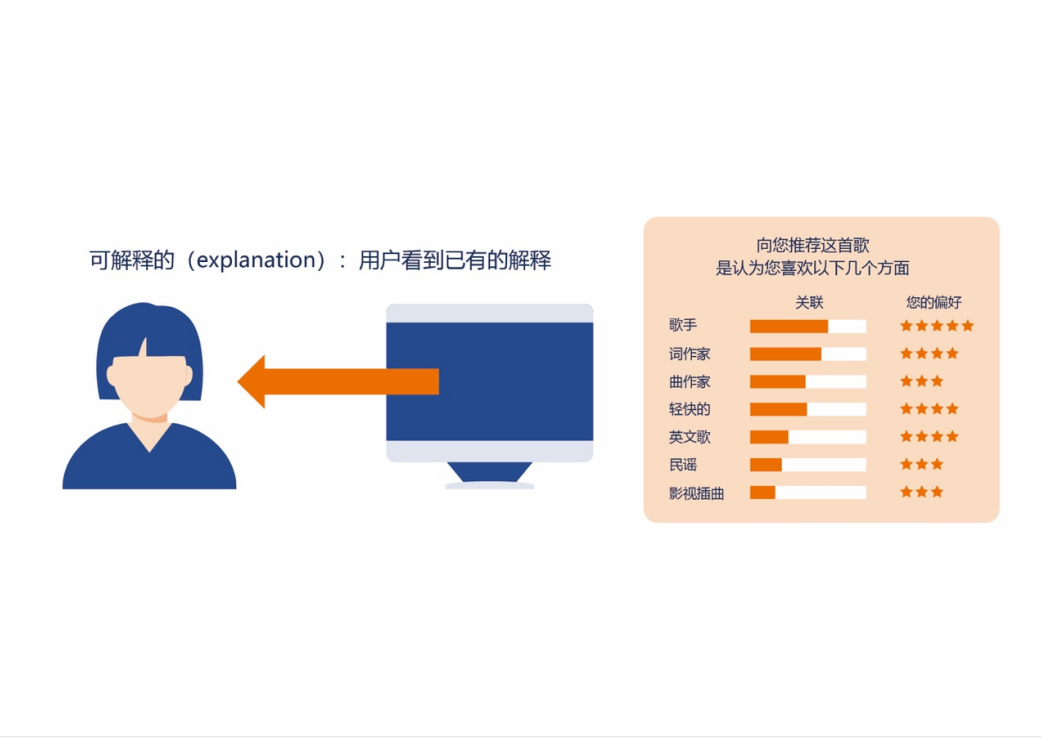
研究在实验室进行。被试被要求在基于算法的音乐网站上观看和使用自动生成的推荐内容(图1),时间约为1小时。该算法基于湖南大学与华为合作项目“智能设计”中的相关算法结果,被试可以通过网站浏览推荐内容。他们被如实告知,这些推荐内容由算法生成,并由机器学习和人工智能机制实现。同时,向被试介绍“公平性、责任、透明度(FAT)”的基本定义。在浏览和使用后,被试被要求完成问卷(表1)。与申东熙的研究相比,本研究修改和删除了部分问题,以符合中国人群的特点。
| 变 量 | 问题 |
| 因果性 | 1.我可以理解这些解释。 2.我不需要帮助来理解这些解释。 3.我发现这些解释有助于我理解因果关系。 |
| 公平 | 1.系统公平。 2.应识别、记录整个算法的数据源及其数据源,并对其进行基准测试。 3.我认为该制度遵循公正的正当程序,没有偏见。 |
| 责任 | 1.我认为该系统需要一名负责人,负责人应及时对其不利的个人或社会影响负责。 2.算法的设计应使第三方能够检查和审查算法的行为。 3.算法应能够仅使用某些操作修改整个配置中的系统。 |
| 透明度 | 1.我认为所用算法的评估和标准应该公开发布,并为人们所理解。 2.算法系统产生的任何输出应向受这些输出影响的人解释。 3.算法应该让人们知道,通过了解算法的外部输出,可以了解算法的内部状态 |
| 可解释性 | 1.我发现算法很容易理解。 2.我认为算法给我提供了足够多的解释。 3.我能理解机器学习的内在机制。我希望这个算法可以解释清楚。 |
| 性能 | 1.我认为推荐的项目反映了我的个性化偏好。 2.我发现推荐的内容非常符合我的需求。 3.我认为算法产生的内容是准确的。 |
| 信任 | 1.我相信算法驱动服务的建议。 2.通过算法过程推荐的项目是可信的。 3.我相信算法服务结果是可靠的。 |
为了评估研究的有效性,本研究进行相关测试以确定变量之间的相互关系。本其检验数据如表2。
| 度量指标 | 均值 | 标准差 | 克朗巴哈系数 | 平均方差 | 综合置信度 |
| 透明度 | 4.604.654.78 | 1.0341.0451.104 | 0.868 | 0.761 | 0.885 |
| 责任 | 4.234.454.06 | 1.2101.1191.025 | 0.758 | 0.759 | 0.904 |
| 公平 | 4.054.234.01 | 1.0251.1431.078 | 0.767 | 0.742 | 0.812 |
| 可解释性 | 4.074.124.25 | 1.2231.2131.207 | 0.749 | 0.709 | 0.799 |
| 性能 | 4.374.094.12 | 1.1321.2831.207 | 0.780 | 0.707 | 0.892 |
| 信任 | 4.394.284.01 | 1.3141.4591.345 | 0.901 | 0.843 | 0.939 |
| 因果性 | 4.013.884.01 | 1.2401.4091.305 | 0.791 | 0.799 | 0.897 |
(4)假设的结构模型试验
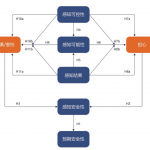
围绕研究的八个假设,对其结构路径进行检验。检验结果表明:除了假设6,所有路径相关系数均具有统计学意义,如表3。从检验结果可以得出初步结论:人类的信任受到“公平性、责任、透明度(FAT)”的显著影响,“公平性、责任、透明度(FAT)”由因果性和可解释性决定。性能受到信任的影响很大。强路径意味着信任与其前因之间的根本联系。算法可解释性的主要影响着人们对信任的感知。
| 路径 | 标准系数 | S.E. | C.R. | P | 支持 |
| H1:可解释性→透明度 | 0.732 | 0.011 | 12.789 | 0.000*** | 是 |
| H2:可解释性→公平 | 0.455 | 0.021 | 3.216 | 0.044* | 是 |
| H3:可解释性→责任 | 0.679 | 0.031 | 13.456 | 0.000*** | 是 |
| H4:因果性→可解释性 | 0.937 | 4.321 | 2.012 | 0.044* | 是 |
| H5:透明度→信任 | 0.531 | 0.056 | 10.051 | 0.000*** | 是 |
| H6:公平→信任 | 0.140 | 0.421 | 1.269 | 0.061 | 否 |
| H7:责任→信任 | 0.350 | 0.058 | 7.281 | 0.002** | 是 |
| H8:信任→性能 | 0.921 | 0.063 | 16.211 | 0.000*** | 是 |
表3 各指标关联
本研究的结论与申东熙相关研究的差别主要在于本研究假设6(公平性到信任)的路径的相关系数不具备统计学意义(p=0.064>0.05),即本研究提出假设6“感知公平性积极影响用户对智能算法的信任”的假设并不成立。本研究中,与假设6相关的假设2(可解释性与公平的相关性)仍然成立,其置信区间为95%。这似乎说明,针对公平性这样的概念,人们报告的感知与实质的感知可能略有差异。这种差异可能直接作用于信任关系。这样的结论可以推论:智能算法必须超越表面的公平性、合法性和准确性,满足人们真正的需求。
(4)结果与讨论
本研究考察了因果关系在机器行为可解释方面的作用以及可解释性如何影响人们的感知与体验。通过实验,本研究表明“因果性”代表了解释的质量,“解释性”与智能机器与系统的质量有关。同时,本研究证实了算法的解释如何通过两种不同的认知途径影响人类的公平性、责任、透明度。从研究得到的关系可以推断:算法特征与人类信任呈正相关。也就是说,人们通过基于“公平性、责任、透明度”的启发法评估,可以提升机器行为(智能算法)的准确性,这种联系可能是关于算法质量、算法体验以及人与智能体交互的关键线索。
更为重要的是,研究结果表明基于信任的可解释性在人与智能体的交互中起着重要作用。人们希望了解算法是如何工作的,其数据是如何被分析的,以及分析结果在多大程度上是公平的甚至是“合理的”。本研究中的模型为通过解释建立信任以及信任的影响因素提供了线索,初步说明了:信任是人与人工智能之间的一种联系机制,也是提高算法性能从而创造以人为本人工智能的重要驱动力。因此,机器行为学在可解释性上的核心在于建立基于信任的反馈回路,这对于设计以人为中心的智能机器与机器行为至关重要。